
はじめに
こんにちは、株式会社AzitでCTOを務めている十亀眞怜(そがめまさと)(@Pocket7878) です。 私たちは日々、さまざまな業務の効率化に取り組んでいますが、その中でも「住所データの処理」は、多くの企業が直面する共通の課題です。
本記事では、日本の複雑な住所体系において、住所を適切に分割・構造化する作業を、AIを活用して半自動化した取り組みについて紹介します。具体的な実装方法や、実運用で得られた知見を共有します。
日本の住所処理が抱える課題
住所体系の複雑さ
日本の住所は世界的に見ても特殊で複雑な構造を持っています。都道府県、市区町村、町名、丁目、番地、号、建物名など、多層的な要素で構成されており、さらに以下のような課題があります:
- 表記の揺れ(漢字/カタカナ、全角/半角、ハイフンの有無など)
- 建物名の多様性(正式名称と通称の混在)
- 企業ごとに異なる住所フォーマットの要求
実際、デジタル庁のベース・レジストリでも、日本の住所の標準化は重要な課題として取り組まれています。
Azitにおける具体的な要件
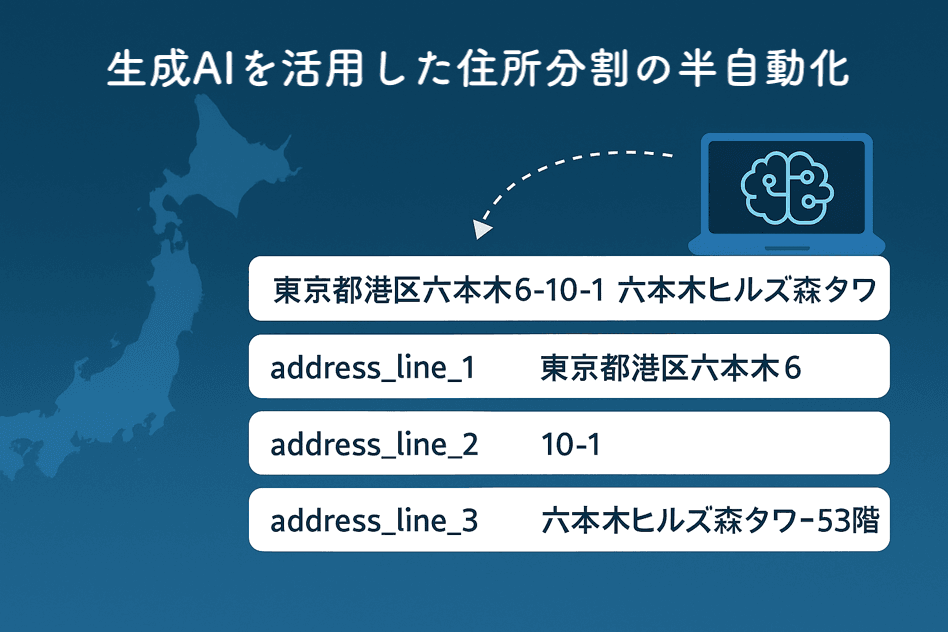
私たちAzitでは、住所データを以下の3つのフィールドに分割する必要がありました:
- address_line_1: 丁目までの住所(例:東京都港区六本木6丁目)
- address_line_2: 番地以降(例:10-1)
- address_line_3: 建物名・部屋番号(例:六本木ヒルズ森タワー53階)
この分割は、システムの都合だけでなく、配送業務やマーケティング分析など、様々な場面で必要となります。
従来の配送依頼の処理では、一件毎にユーザーが入力していたため、上記の3つのフィールドに分割する作業はユーザーが実施してくれていました。
しかし、今回はユーザーの社内独自フォーマットのファイルを弊社側のオペレーションで上記の弊社側の形式に沿ったフィールドに分割したファイルに変換して一括入稿する必要がありました。
そのため、数十〜百件ほどの配送依頼を一回で取り扱う必要が発生し、この変換業務をいかに効率的にするかが重要となりました。
既存ソリューションの限界
当初、Google Maps APIなどの既存サービスの活用を検討しましたが、Google Mapは前述のような複雑な日本の住所には十分には対応できておらず、たとえば番地以下をGoogle Mapではそもそも認識できていなかったりするなど、住所文字列を分割するという観点では利用が困難でした。一方で、Google Maps APIには住所が誤っていてもランドマーク名などが含まれていれば、おおよそ正しい位置を認識できるといった特性があります。
このように住所情報の処理という観点では
- 集合知的なアプローチによって「曖昧ではあるが、柔軟に住所を処理できる」ツール
- 厳密なルールやマスターデータによって「厳密な住所を厳密に処理できる」ツール
の間のグラデーションで様々なAPIや手段やツールが存在します。
今回のケースでは、厳密に住所を分割したあと弊社のシステムに沿った形式に結合し直すというアプローチも考えられますが
元々の住所が厳密なのかという観点や厳密に住所を分割するためのシステムを構築するコストにたいして今回の対象となる運用においてどの程度の厳密さが求められるのかのバランスを考えた際に、より前者に近い曖昧でも良いので柔軟に住所を処理できる方式を探ることとしました。
事実、本機能の対象となった顧客から送付されるデータの中には丁目や番地などが省略されているが、ランドマークとなるような有名なビル名がふくまれているデータなどが入っており、厳密な住所である前提での正規化などは困難であろうと判断しました。
発想の転換:完璧な自動化から半自動化へ
上記について話し合いを進める中で、チームメンバーから「完全な自動化を実現しなくても、AIで候補を出してもらって、人間がチェックすれば良いのでは?」という提案がありました。
これは音声認識のコーパス作成で同様の手法(TTSで読み上げ→人間がレビュー)でサンプルデータを作った事例からの着想でした。
そこで完璧な自動化を目指すのではなく、「AIが候補を生成し、人間が最終確認する」という現実的なアプローチを検討することにしました。
Anthropic Claude APIの活用
様々なAIモデルを検証した結果、Anthropic Claude 4 Sonnetが最も良い結果を出しました。 少し工夫をした点としては、Prefill機能を使った確実なJSON出力の実現です。
実装の詳細
プロンプトエンジニアリング
以下が実際に使用したプロンプトです:
user_prompt = """あなたは日本国内の住所の文字列を処理するプログラムです。
住所リストの各住所を適切に処理してください。
出力は以下のJSON形式に従ってください:
[
{
"original_address": "元々の住所の文字列そのまま",
"address_line_1": "住所の「丁目まで」の文字列",
"address_line_2": "住所の「番地以降」の文字列",
"address_line_3": "住所の「建物名・部屋番号」の文字列"
},
...
]
住所リスト:
{ADDRESS_LIST}"""
# 重要:Prefillで配列の開始を指定
assistant_prefill = "["
Prefill機能の重要性
Prefillを使わない場合、以下のような問題が発生します:
// 望まない出力例1:Markdownのコードブロック
```json
[
{
"original_address": "..."
}
]
// 望まない出力例2:余分な説明文
以下が処理結果です:
[
{
"original_address": "..."
}
]Prefillで [ を先に出力させることで、これらの問題を回避し、純粋なJSONのみを取得できます。
実装コード例
import anthropic
import json
def build_user_prompt(address_list: list[str]) -> str:
address_list_str = "\\n".join(f'"{index}. {address}"' for index, address in enumerate(address_list, start=1))
return f"""
あなたは日本国内の住所の文字列を処理するプログラムです。
住所リストの各住所を適切に処理してください。
出力は以下のJSON形式に従ってください:
[
{{
"original_address": "元々の住所の文字列そのまま",
"address_line_1": "住所の「丁目まで」の文字列",
"address_line_2": "住所の「番地以降」の文字列",
"address_line_3": "住所の「建物名・部屋番号」の文字列"
}},
...
]
住所リスト:
{address_list_str}
""".strip()
def split_addresses(address_list: list[str]) -> list[dict]:
"""
Splits a list of Japanese addresses into structured components.
Args:
address_list (list[str]): List of addresses to be processed.
Returns:
list[dict]: List of dictionaries containing structured address components.
"""
# Build the user prompt
user_prompt = build_user_prompt(address_list)
# Initialize the Anthropic client
client = anthropic.Anthropic(
api_key=os.environ.get("ANTHROPIC_API_KEY"),
)
# Replace placeholders like {{ADDRESS_LIST}} with real values,
# because the SDK does not support variables.
message = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=8192,
temperature=1,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": user_prompt,
}
]
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "["
}
]
}
]
)
# 結果の先頭に[を結合して、JSONとして処理する
result_json_str = f"[{message.content[0].text.strip()}"
result_json = json.loads(result_json_str)
return result_json
# 使用例
parser = AddressParser(api_key="your-api-key")
addresses = [
"東京都港区六本木6-10-1 六本木ヒルズ森タワー53階",
"兵庫県神戸市中央区三宮町1-9-1 センタープラザ東館4階",
"静岡県浜松市中区砂山町320-2 浜松メイワン8階"
]
results = parser.parse_addresses(addresses)
実際の処理例と結果
入力データ(サンプル)
1. 東京都港区六本木6-10-1 六本木ヒルズ森タワー53階
2. 兵庫県神戸市中央区三宮町1-9-1 センタープラザ東館4階
3. 静岡県浜松市中区砂山町320-2 浜松メイワン8階
4. 茨城県つくば市吾妻1-9-2 つくばセンタービル3階301号室
5. 長野県松本市中央1-23-1 松本市役所3階
出力結果
[
{
"original_address": "東京都港区六本木6-10-1 六本木ヒルズ森タワー53階",
"address_line_1": "東京都港区六本木",
"address_line_2": "6-10-1",
"address_line_3": "六本木ヒルズ森タワー53階"
},
{
"original_address": "茨城県つくば市吾妻1-9-2 つくばセンタービル3階301号室",
"address_line_1": "茨城県つくば市吾妻",
"address_line_2": "1-9-2",
"address_line_3": "つくばセンタービル3階301号室"
}
// ... 以下省略
]
モデル比較
ベースとなるプロンプトや生成結果の確認はAnthropicのWorkbenchの画面でプロンプトの内容やサンプルと期待する出力を様々なパターンを設定しながら確認しました。
精度がある程度高く、また一方で無用に高度なLLMモデルを選択するのもコスト面や処理実行時間面でももったいないので、いくつかのモデルを比較しました。
Claude 3.5 Sonnetと4 Sonnetを比較した結果:
- Claude 3.5 Sonnet: 単純に数字が始まったら分割するなど、判断が甘い
- Claude 4 Sonnet: より正確な判断で、日本の住所構造を理解した分割が可能
といった所もサンプルのデータからわかり、今回はClaude 4 Sonnetをモデルとして選択することとしました。
運用での成果と知見
このようにデータを自動的にAIによって自動分割することで、従来は人間が一件ずつチェックして切り貼りが必要だったステップが、人間は目視でレビューをしていくだけで確認が可能になり、大幅に作業時間が短縮されました。
元々の生の住所もレビュー用のデータとして残すことで、ハルシネーションによってまったく異なる住所が出力されてしまっているようなケース(実際には発生していませんが)にも気がつけるようになっています。
今後の展望
機能拡張の可能性
- ランドマーク対応: 「東京タワー」「丸の内ビルディング」など、有名建築物の自動補完
- 表記揺れの統一: カタカナ/漢字、全角/半角の自動正規化
- エラー検出: 明らかに間違った住所の自動検出とアラート
他業務への横展開
この「AI+人間レビュー」のアプローチは、住所処理以外にも応用可能です:
- 商品カテゴリの分類
- 顧客データのクレンジング
- ドキュメントのメタデータ付与
まとめ
日本の複雑な住所体系に対して、生成AIを活用した半自動化アプローチを実装しました。重要なのは、AIを「完璧な自動化ツール」としてではなく、「人間の作業を効率化するアシスタント」として位置づけたことです。
Prefill機能のような技術的なテクニックを活用することで、より確実で実用的なシステムを構築できました。この事例が、同様の課題に直面している方々の参考になれば幸いです。