to Developer
OpenAI Realtime APIでAI電話を作った話
2025.12.18
Iwase Takeshi

はじめに
株式会社Azitでエンジニアリングマネージャをしている岩瀬です。
私たちは物流・SCM領域に特化したAIソリューションを提供しています。SCM領域のDXを進める中で気づいたのは、どれだけシステム化を進めても、現場には「電話」という最後の壁が残っているということでした。倉庫や配車の現場では車両の誘導や日程調整を電話で回していることが多く、営業部門も架電に相当なリソースを割いています。
そこで私たちは、音声AIを使った電話業務の自動化に挑戦することにしました。2024年12月から2025年3月にかけて、MVP開発として「AIがどの程度電話業務の穴を埋められるのか」「人と同じレベルの会話体験をどこまで作れるのか」を検証しました。
今回は、そのMVP開発で経験した試行錯誤と学びについて振り返ってみたいと思います。音声AIを使った開発に興味のある方、AIの可能性と限界を知りたい方の参考になれば幸いです。
※本稿は半年前に実施したMVP開発の振り返りです。当時遭遇した課題の一部は、現在の技術アップデートで改善されている可能性があります。
プロジェクト概要
目的と目標
このMVP開発の主な目的は以下の3点でした。
- AI電話プロダクトが商品として販売可能かの仮説検証
- 顧客が導入後をイメージできるデモを提示できる状態にすること
- インフラの固定・従量費用を具体的に把握すること
ローカル環境で技術検証をするだけではなく、Twilio + Azure OpenAI Realtime APIを使ってサーバ上で動作する「製品に近い構成」を目指しました。
シナリオ選定
今回は2つのシナリオを開発しました。
車両誘導(受電) ドライバーから電話を受けて、車番とドライバー名から予定情報を照合し、次の目的地や明日の予定、その住所や積載物などをAIがドライバーに伝達するシナリオです。日々の電話件数が多く、AIによる一次対応のニーズが顕在化していました。
営業架電 見込み顧客に対して、サービスの紹介と打ち合わせの日程調整を行うシナリオです。オペレーターのリソースが限られており、効率化のインパクトが大きい領域でした。
受電と架電それぞれで課題や効果がどう違うかを比較することも狙いの一つでした。
役割分担
私(岩瀬)が進捗管理、基本設計、シナリオ設計、プロンプト作成を担当し、CTOの十亀さんが詳細設計と開発(インフラ構築・コーディング)を担当しました。
システム構成
全体構成
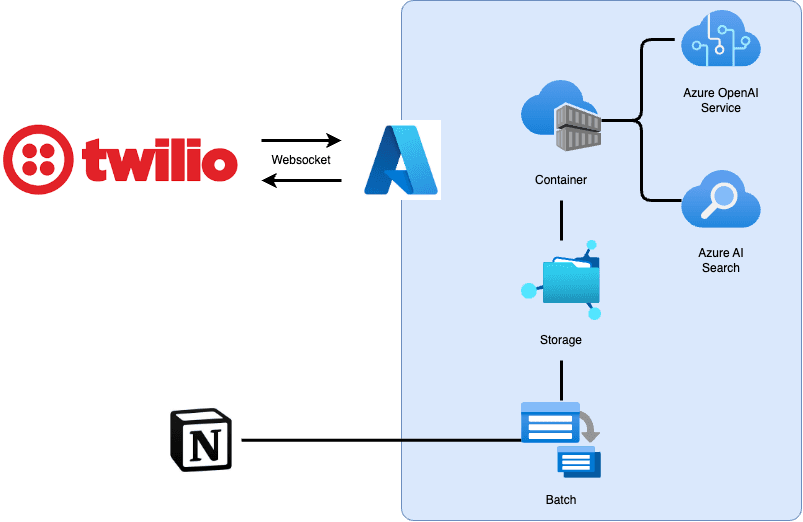
システムは大きく分けて、電話を受け持つTwilio側と、音声処理を行うAzure側で構成されています。
処理の流れ:
- Twilioが電話を受信し、WebSocket経由でAzure上のコンテナに接続
- コンテナがAzure OpenAI Realtime APIに接続し、音声の送受信を行う
- 必要に応じてAzure AI Searchを使ってRAG(検索拡張生成)を実行
- プロンプトやRAG用データはNotionで管理し、バッチ処理でストレージに同期
この構成は、Microsoftの公式サンプル(aisearch-openai-rag-audio)をベースに構築しました。
各サービスの役割
Twilio 電話の受発信を担当します。着信したらWebhookでAzure上のコンテナに接続し、音声データのストリーミングを行います。
Azure OpenAI Realtime API 音声の入力と出力をリアルタイムで処理する、今回のシステムの中核です。従来のText-to-Speech/Speech-to-Textを組み合わせる方式と異なり、音声を直接入力して音声を直接出力できます。これにより低遅延の会話が可能になります。
Azure AI Search RAGに使用します。プロンプトやFAQなどの情報をインデックス化し、会話の文脈に応じて必要な情報を検索・提供します。
Notion プロンプトやRAG用データの管理に使用しました。
構成検討の経緯
当初はDifyを使ってRAGを管理する構成を検討しました。しかし、Difyでリアルタイムの会話を扱おうとするとWebSocket接続に制約が多く、Twilioとの音声接続も難しいことがわかり断念しました。
Twilio単体でもテキスト読み上げは可能ですが、会話の途中で割り込めるようなリアルタイム性が欲しかったため、Azure OpenAI Realtime APIを選定しました。
また、プロンプトやRAGデータの管理にNotionを選んだのは、非エンジニアでもシナリオを編集できるようにする狙いがありました。ただし後述するように、途中でMarkdownファイルへの外部化に変更することになります。
なお、Realtime APIはリージョンに制限があり、当時はNorth Central USでのみ動作することを確認しています。
開発の流れと試行錯誤

Phase1:調査・準備(12月〜1月)
最初の2ヶ月は、技術調査とMVP開発に向けた準備計画に費やしました。
主な作業内容は以下の通りです。
- 既存の音声AIスタックの調査
- システム構成の検討と技術選定
- Azure環境の構築(ACR Tasks権限エラーやリージョン問題への対処)
- Twilio-Azure OpenAI Realtime API連携の検証
- Notion連携の検討
- 費用試算(月額5万円規模)
特にAzure環境の構築では、無料枠ではACR Tasksが使えないことや、リージョンによって動作しないことがあり、試行錯誤が必要でした。十亀さんがこれらの技術的な課題を一つずつクリアし、ローカル環境でTwilioとRealtime APIを接続して会話できることを確認しました。
Phase2:MVP開発と問題の発生(2月)
2月からMVP開発を本格的に開始しました。車両誘導と営業架電の両シナリオを並行して開発し、実際に電話をかけて動作を確認しました。
当初は「バージイン(AIが話している途中でも人が割り込める設定)」で開発を進めました。より自然な会話に近づけたいという狙いでしたが、ここで深刻な問題に直面します。
相槌で会話が破綻する問題
最も深刻だったのが、人が「はい」「えぇ」「うんうん」といった相槌を打つと、AIの発話が中断してしまう問題でした。
これはRealtime APIのVAD(Voice Activity Detection:音声検出)機能が、人の発話を検知するとAIの発話を即座に中断する仕様によるものです。意味のある発言と相槌を区別できないため、相槌も「人が話し始めた」と認識してしまいます。
さらに問題だったのは、AIの発話が中断されると、プロンプトで指定した会話の流れを無視して次に進んでしまうことでした。例えば、営業シナリオでサービスの詳細を説明している最中に相槌を打たれると、説明を飛ばして次の質問に進んでしまいます。会話が完全に破綻してしまうのです。
その他の問題
相槌問題以外にも、多くの問題が発生しました。
- 人の発言に関係なく音声が途切れる
- 漢字や数字の読み方が間違っている
- 名前や電話番号の照合がうまくいかない
- 会話のフローを飛ばしてしまう
これらの問題の詳細は後述しますが、2月の時点では「このままでは実用化は難しい」という状況でした。
Phase3:大きな転換点(3月)
3月上旬、プロジェクトにおける大きな転換点がありました。2つの抜本的な改善を実施したのです。
1. ターン制への切り替え
バージインから、「ターン制(AIと人が交互に話す設定)」への切り替えを決断しました。
ターン制では、AIの発話が完了してから人の発話を受け付けます。Twilioのmark機能を使って、AIの発話完了を管理する実装を行いました。実際にはoutgoing_call_turnとして別のコードベースで管理しています。
この変更により、相槌でAIの発話が中断される問題は解消されました。バージインによる自然な会話は失われましたが、会話のフローが飛ぶ問題はほぼ解消し、会話の安定性が大幅に向上しました。
意外だったのは、人は思った以上に相手の発話終了を待てるということです。「待たされ感」を心配していましたが、実際にはそれほど大きな違和感はありませんでした。
2. プロンプトの構造化
もう一つの大きな改善が、プロンプトの外部化と構造化です。
当初はNotionのページをそのまま読み込んでいましたが、Notionから取得したテキストは構造が崩れており、AIが会話のフローを正しく認識できていない可能性がありました。単に相槌で会話が飛ぶだけでなく、そもそもフローの理解が曖昧だったのです。
そこで、プロンプトをNotionからMarkdownファイルへ外部化し、見出しや箇条書きを使って明確に構造化して記述しました。これにより、AIが会話のフローを正しく認識できるようになり、意図通りに動作する確率が高まりました。
また、一時期プロンプトをコードにベタ書きしていたこともあり、Notionを更新しても反映されないという事故も経験しました。外部化することで、デプロイなしでシナリオを更新できるようになり、開発効率も向上しました。
ターン制への切り替えは「相槌による中断」を防ぐための対策、プロンプトの構造化は「フローの正しい認識」を実現するための対策です。似ているようで目的は異なりますが、両方を実施することで相乗効果が生まれました。
成功体験
この2つの改善を実施した後、初めて電話をかけたときのことは今でも覚えています。
間が空かず、発話が被らず、想定したフローに沿って会話が進む。目を瞑れば人っぽい、という段階にまでたどり着けたのです。この瞬間は、プロジェクトを通じて最も手応えを感じた瞬間でした。
そして何より、当初の目標であった「実際にAIと会話ができるデモを顧客に提示できる状態」を実現できたことが大きな成功でした。完璧ではないものの、電話をかけてAIと会話し、シナリオに沿ったやり取りができる。この実動するデモを提示できたこと自体が、プロジェクトの大きな成果でした。
Phase4:プロダクト機能の拡充(4月)
Phase3で想定通りの会話が実現できるようになった後、次のステップとしてプロダクトを顧客に提案するための機能追加に取り組みました。自社の営業が顧客に説明しやすく、かつ実際の業務で使えるイメージを持ってもらえるような機能を実装していきました。
この時期に実装した機能は以下の通りです:
プロンプトチェイニング
フロー遵守をさらに確実にするため、Function Callingを活用した「プロンプトチェイニング」を試しました。これは、最初に会話全体のフローをすべて渡すのではなく、関数を呼び出すとその結果として次のステップの指示が返ってくる仕組みです。
例えば、「ユーザーが興味を示したと判断したらinterest_matching_service関数を呼び出してください。関数の結果に次の指示が含まれています」という形で、段階的にプロンプトを切り替えます。
劇的な変化があったわけではありませんが、フロー遵守の確実性が増したと感じました。
会話の記録と要約
電話業務では、誰とどんな話をしたかを記録することが重要です。そこで以下の機能を実装しました:
- 会話の文字起こしをデータベースに記録
- AIが会話内容を要約し、スプレッドシートに議事録として出力
- 通話終了後にSMSで定型メッセージを送信
特に要約機能は、後から会話内容を振り返る際に有用な機能として、デモでも好評でした。
日程調整の自動化
実際の電話営業を想定し、「打ち合わせの日程調整」を自動化する機能を実装しました。Googleカレンダーと連携させることで、実務での活用シーンを具体的にイメージしてもらえるようにしました。
AIがカレンダーから空き時間を取得し、「4月21日の9時から10時まで、10時30分から12時まで...」といった候補を読み上げます。ここで工夫したのは、日程を形態素解析ツールでカタカナの読み仮名に変換したことです。「シガツニジュウイチニチノクジカラジュウジマデ」のように変換することで、読み間違いを防ぎました。
相手が希望する日程が決まれば、そのままカレンダーに予定を登録します。日程調整が完了する前に通話が切れた場合は、SMSを送らないように制御も加えました。
架電リストとの連携
電話営業の業務フローを再現するため、架電リストを読み取って自動で電話をかけ、通話後にチェックマークや議事録を追加する機能も実装しました。
これらの機能は、すべて実験的な実装でしたが、「AI電話を実際の業務フローにどう組み込むか」を考える上で重要な試行錯誤でした。
発生した問題の全体像
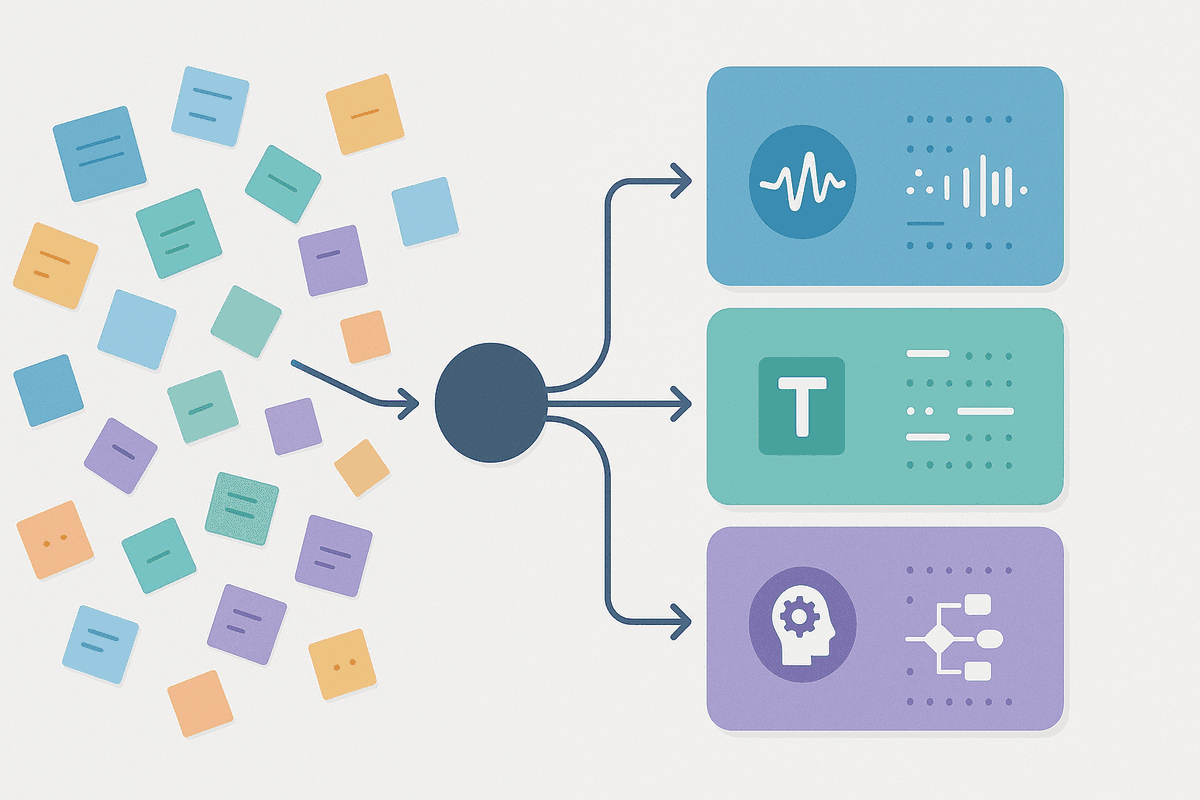
MVP開発を通じて発生した問題を整理すると、以下の4つのカテゴリに分類できます。開発時には個別に対処していましたが、振り返ってみると問題の性質ごとに分類できることがわかりました。
音声出力の問題
相槌で音声が切れる
前述の通り、最も深刻だった問題です。AIが話している最中に人が「はい」「うんうん」「へー」といった相槌を打つと、AIの発話が途中で停止し、会話のフローが飛んでしまいます。
音声が途切れる
人の発言に関係なく、AIの音声が途中で途切れることもありました。文章の区切りで途切れる場合と、単語の途中で切れる場合があり、原因の特定が困難でした。
通信の遅延や処理の影響が考えられますが、明確な原因は特定できませんでした。
速度・発音・イントネーションの揺らぎ
同じ会話でも、AIの話す速度やイントネーションが一定ではありませんでした。録音して聴き比べると、極端に早くなったり遅くなったり、一瞬別人のように聞こえることもありました。
また、発音が不明瞭になり「噛んだ」ように聞こえることもありました。例えば「お打ち合わせ」が「おとうあわせ」に聞こえるといった具合です。
これは音声処理の性能、特に当時のRealtime APIが英語に最適化されており、日本語への最適化が十分でなかったことが原因と考えられます。
読み上げの問題
漢字の読み方が違う
地名の読み方を間違えることが頻繁にありました。
- 「目黒区三田」の「三田」を「みた」ではなく「さんだ」と読む
- 「葛飾区新宿」の「新宿」を「にいじゅく」ではなく「しんじゅく」と読む
メジャーな読み方が優先されてしまい、マイナーな読み方は使われにくいようです。
日付・番地の読み方が違う
日付や住所の番地の読み方も問題でした。
- 「1日」を「ついたち」ではなく「いちにち」
- 「20日」を「はつか」ではなく「にじゅうにち」
- 「1/3」を日付ではなく分数として読む
特殊な読み方がある日付は壊滅的に間違えることがありました。
数字の読み方がおかしい
電話番号のような桁数の多い数字では、読み違える率が非常に高くなりました。
- 数字を飛ばす:「09011001234」→「ぜろきゅういちいちぜろいちにさん」
- 違う数字を読む:「09011001234」→「ぜろきゅういちにさんぜろさんよんごろく」
- 桁を混同する:「09011001234」→「ぜろきゅうぜろせんひゃくじゅうにさんじゅうよん」
電話番号として認識している場合と、単純な数字の並びとして認識している場合が混在し、読み方が安定しませんでした。
理解・判断の問題
照合の精度が低い
名前や電話番号などを人に言わせて、AIがデータと照合する処理がうまくいきませんでした。例えば、人が伝えた4桁の車番とデータにある車番の照合が正しく行われないことがありました。
AIは単語や文節に区切って前後関係で処理しているため、完全一致や前方一致といった厳密な照合が難しいようです。数字の照合は特に壊滅的でした。
判断が人と異なる
「興味がある場合」と「興味がない場合」で分岐させる際に、人間とは異なる判断をすることがありました。
例えば、「あります」と回答した場合は「興味がない」の分岐に入り、「はい、あります」と回答した場合は「興味がある」の分岐に入るといった具合です。
日本語的な曖昧な言い回しをうまく処理できないことが原因と考えられます。
フロー制御の問題
フローを遵守できない
会話のフローを指示しても、フローを飛ばしたり指示通りに分岐できなかったりすることがありました。
- 概要を説明した後に詳細を説明すると指示しているのに、詳細の説明を飛ばす
- 質疑応答をしてから日程の調整をすると指示しているのに、質疑応答を飛ばす
プロンプトでフローチャートを表現しにくいこと、AIが前後関係で処理しているためフロー全体を把握できていないことが原因と考えられます。
指示を無視する
プロンプトの指示を守らなかったり、部分的に抜かしたりすることもありました。
- 「早口で話してください」と指示しても早口にならない
- 「復唱してください」と指示しても復唱しない
- 禁止事項を守らない
実行時の優先度や遵守度合いに揺らぎがあり、指示が厳格に守られるわけではないようです。
デモでの反応

社内外に向けてデモを実施し、様々な反応を得ることができました。
ポジティブな反応
音声で「人みたいに話す」ことへの驚きは予想以上に大きいものでした。AIがリアルタイムで応答し、自然に会話できることに対して、純粋な驚きと興味を示していただけました。
ターン制に切り替えた後は、シナリオ逸脱が減ったことに対して前向きな評価も得られました。
課題の指摘
一方で、デモ中に問題が露呈することもありました。無音や読み間違い、相槌対応の問題が出ると、評価は一気に下がりました。
特に印象的だったのは、顧客の期待値の高さです。顧客は「人の代替」を前提として見ており、100%に近い精度を期待されていました。少しでも問題が出ると「まだまだ」という評価になります。
料金に対する強い反応は少なかったものの、割高感の指摘はありました。関心は常に「人の代替ができるか」に集中しており、補助的な活用という提案は受け入れられにくい印象でした。
音声AI開発で学んだ教訓
このプロジェクトを通じて得た重要な教訓をまとめます。
1. AIは想像以上に人のように話せるが、人の期待値はさらに高い
最も驚いたのは、AIが想像以上に人のように話せるということでした。技術の進歩は予想を上回っており、適切に設定すれば「目を瞑れば人っぽい」レベルの会話が実現できます。定型的な会話や、感情を考慮しなくてよい会話は、すでにAIで実施可能なレベルにあります。
しかし、人の期待値は現状の技術を上回っています。
顧客はAIに「人と同等かそれ以上」を求めており、100%に近い精度を期待しています。「人の手が回らないところを補助させる」という提案は、なかなか受け入れられません。
さらに興味深かったのは、人間には寛容なのにAIには厳しいという反応です。言い間違いやイントネーション、発音の揺らぎなど、人間でも起こることに対して、AIがやると目くじらを立てられることが多くありました。電話で人が対応していたら大抵無視するレベルの小さなミスでも、AIだと「システムなのに」と厳しく指摘されるのです。
現時点では人の期待値が過剰であり、AIの適切な活用領域を理解してもらうことが大きな課題だと感じました。
2. AIのランダム性との付き合い方が難しい
AIの発言にはランダム性があり、それがよく働くこともあれば、悪く働くこともあります。
よく働く例としては、会話が自然になることが挙げられます。毎回全く同じ言い回しではなく、微妙に表現を変えることで、人間らしさが生まれます。
一方で、悪く働く例としては、指示を守らなかったり、重要な情報を言い間違えたりすることがあります。特に電話番号や住所といった厳密性が求められる情報で問題が出ると、実用上大きな支障になります。
だからといって厳密性を求めてランダム性を完全に排除すると、既存の音声案内のようになってしまいます。「ただいま、サービスの、ご案内を、いたします」といった機械的な話し方では、AIを使う意味が薄れてしまいます。
自然さと正確さのバランスをどう取るかが非常に難しいと感じました。用途によって最適なバランスは異なるため、一律の答えはなく、個別に調整していく必要があります。
3. システム設計とプロンプト設計の両面からのアプローチが必要
音声AI開発では、技術的な実装だけでなく、プロンプト設計が非常に重要であることを実感しました。
ターン制への切り替えはシステム側の対応、プロンプトの構造化はプロンプト側の対応です。どちらか一方だけでは不十分で、両面からアプローチすることで相乗効果が生まれました。
また、問題が発生したときに、それがAIの限界なのか、プロダクトの実装で解決できることなのかの切り分けに多くの時間を費やしました。この切り分けができないと、適切な対策を打てません。
音声AI開発は、システムエンジニアリングとプロンプトエンジニアリングの両方のスキルが求められる領域だと感じました。
おわりに
今回のMVP開発は、音声AIの可能性と課題を実感できる貴重な経験となりました。
技術的には、相槌や復唱を「無視してよい発言」として聞き分ける精度向上や、地名・日付・数字の読み上げ品質の改善が今後の課題です。OpenAI Realtime APIはturn-takingの改善や速度調整パラメータなど、日々新しい機能が追加されており、これらの課題も近い将来解決される可能性があります。
私たちAzitでは、ForecastX(需給予測)やDeliveryX(配車最適化)といったSCM領域のAIソリューションを提供しており、今回の音声AIもその一環として検証を行いました。AIを活用した新しいソリューションの開発に興味のある方、一緒に挑戦したい方は、ぜひお気軽にお声がけください。
最後まで読んでいただき、ありがとうございました。